


Federated Learning (FL) es un paradigma de Machine Learning (ML) introducido por Google en 2016, en el que muchos clientes (por ejemplo, dispositivos móviles o varias organizaciones) entrenan de forma colaborativa un modelo bajo la orquestación de un servidor central (por ejemplo, un proveedor de servicios), manteniendo en todo momento los datos de entrenamiento descentralizados. Encarna los principios de recopilación centrada, minimización de datos, y puede mitigar muchos de los riesgos y costes de privacidad sistémicos resultantes del ML tradicional y centralizado.
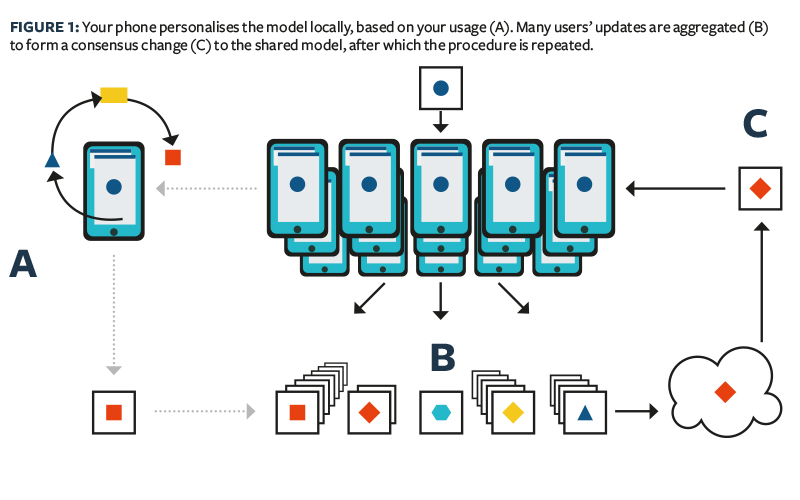
Aunque el análisis de datos con preservación de la privacidad se ha estudiado durante más de 50 años, sólo en la última década se han desplegado soluciones a gran escala. Por ejemplo, el FL entre dispositivos y el análisis de datos federados se están aplicando ahora en los productos digitales de consumo. Google utiliza ampliamente el aprendizaje federado en el teclado móvil Gboard, así como en las funciones de los teléfonos Pixel y en Android Messages. Aunque Google ha sido pionero en la aplicación de FL entre dispositivos, el interés en este entorno es ahora mucho más amplio, y otras empresas ya lo están aplicando: Apple está utilizando FL entre dispositivos desde iOS 13, para aplicaciones como el teclado QuickType y el clasificador vocal de «Hey Siri»; doc.ai está desarrollando soluciones FL entre dispositivos para la investigación médica y Snips ha explorado la FL entre dispositivos para la detección de palabras clave.
Aunque el término FL se introdujo inicialmente haciendo hincapié en las aplicaciones de dispositivos móviles y de edge, ha aumentado mucho el interés por aplicar el FL a otras aplicaciones, incluidas algunas que podrían implicar sólo un pequeño número de clientes relativamente fiables, por ejemplo, múltiples organizaciones colaborando para entrenar un modelo. Estos dos escenarios de FL se denominan «cross-device» y «cross-silo» respectivamente. Existen múltiples ámbitos en los que se ha planteado la aplicación de FL en escenarios «cross-silo». Como ejemplo podemos mencionar la predicción de riesgos financieros para el reaseguro, el descubrimiento de productos farmacéuticos, la minería de registros sanitarios electrónicos, segmentación de datos médicos, fabricación inteligente u otras aplicaciones relacionadas directamente con los sistemas de transporte de las Smart Cities (mejora de las comunicaciones entre vehículos, vehículos eléctricos y vehículos autónomos).
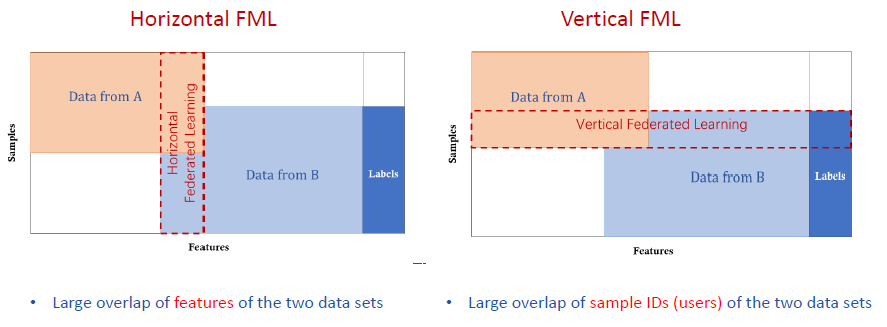
Existe además una división del FL en función de la separación existente en los datos con los que se trabaje. El caso más común, aplicable a los dispositivos móviles, es el del FL horizontal (u homogéneo). En este caso, hace referencia a datos horizontales, es decir, datos que contienen las mismas propiedades (features) para cada individuo. En el lado opuesto se encuentra el FL vertical (o heterogéneo) en los que dos datasets contienen las mismas muestras, pero con propiedades diferentes. Por ejemplo, el banco y el supermercado pueden contener datos diferentes de un mismo cliente. Este último tipo de FL es más complejo, pero también es aplicable y de especial utilidad para los escenarios de Smart Cities donde los ciudadanos son usuarios de múltiples servicios.