


En el federated learning, un servidor central organiza el proceso de formación y recibe las contribuciones de todos los clientes, por lo tanto, también representa potencialmente un único punto de falla. De esta manera, es posible que un servidor central confiable y potente no siempre esté disponible o sea deseable en escenarios de aprendizaje más colaborativo, pudiendo incluso convertirse en un cuello de botella cuando el número de clientes es muy grande.
La idea clave del aprendizaje completamente descentralizado es reemplazar la comunicación con el servidor por una comunicación de igual a igual entre clientes individuales.
En algoritmos completamente descentralizados, una “round” corresponde a que cada cliente realice una actualización local e intercambie información con sus vecinos en el gráfico. En el contexto del machine learning, la actualización local suele ser un local (stochastic) gradient step y la comunicación consiste en promediar los parámetros del modelo local con los vecinos.
Hay que tener en cuenta que ya no existe un estado global del modelo como en el federated learning estándar, pero el proceso se puede diseñar de manera que todos los modelos locales converjan a la solución global deseada, es decir, los modelos individuales alcanzan gradualmente el consenso.
En el entorno descentralizado, una autoridad central aún puede estar a cargo de establecer la tarea de aprendizaje para decidir cuestiones como el modelo a entrenar, el algoritmo a usar, los hiperparámetros… Alternativamente, las decisiones también pueden ser tomadas por el cliente que propone la tarea de aprendizaje, o de forma colaborativa a través de un esquema de consenso.
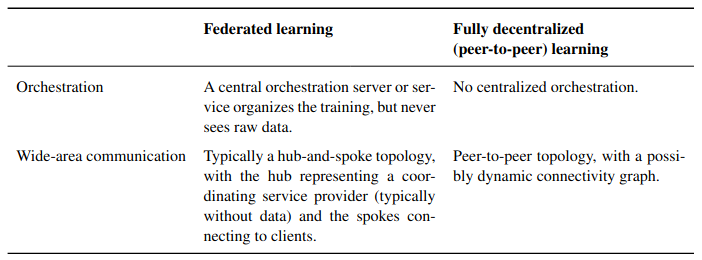 Esta tabla muestra una comparación de las distinciones clave entre el federated learning y el aprendizaje completamente descentralizado
Esta tabla muestra una comparación de las distinciones clave entre el federated learning y el aprendizaje completamente descentralizado
Desafíos algorítmicos
Una gran cantidad de preguntas algorítmicas importantes permanecen abiertas sobre el tema de la usabilidad en el mundo real de los esquemas descentralizados para el aprendizaje automático.
Efecto de la topología de red y la asincronía en SGD descentralizados
Los algoritmos completamente descentralizados para el aprendizaje deben ser robustos para la disponibilidad limitada de los clientes (con clientes temporalmente no disponibles, que se desconectan o se unen durante la ejecución) y la confiabilidad limitada de la red (con posibles caídas de mensajes) .
Las redes bien conectadas o más densas fomentan un consenso más rápido y brindan mejores tasas de convergencia teórica, que dependen de la brecha espectral del gráfico de red. Sin embargo, cuando los datos son IID, las topologías más dispersas no perjudican necesariamente la convergencia en la práctica.
La mayoría de los trabajos de teoría de optimización no consideran explícitamente cómo la topología afecta el tiempo de ejecución, es decir, el tiempo de reloj de pared requerido para completar cada iteración de SGD.
Las redes más densas suelen sufrir retrasos en la comunicación que aumentan con los grados del nodo.
La propuesta MATCHA es un método SGD descentralizado basado en el muestreo de descomposición coincidente, que reduce el retraso de comunicación por iteración para cualquier topología de nodo mientras mantiene la misma velocidad de convergencia de errores. La idea clave es descomponer la topología del gráfico en coincidencias que consisten en enlaces de comunicación separados que pueden operar en paralelo y elegir cuidadosamente un subconjunto de estas coincidencias en cada iteración.
SGD descentralizado de actualización local
El análisis teórico de esquemas que realizan varios pasos de actualización local antes de una «round» de comunicación es significativamente más desafiante que aquellos que usan un solo paso de SGD.
En general, la comprensión de la convergencia bajo distribuciones de datos que no son IID y cómo diseñar una política de promedio de modelo que logre la convergencia más rápida sigue siendo un problema abierto.
Personalización y mecanismos de confianza
Diseñar algoritmos para aprender colecciones de modelos personalizados, es una tarea importante, para distribuciones de datos que no son IID
Nuevos artiulos han presentado algoritmos que ayudan a aprender en colaboración un modelo personalizado para cada cliente suavizando los parámetros del modelo entre clientes que tienen tareas similares (distribuciones de datos similares).
A pesar de los avances, la solidez de tales esquemas para los actores maliciosos o la contribución de datos o etiquetas no confiables sigue siendo un desafino clave, ya que el uso de incentivos o el diseño de mecanismos en combinación con el aprendizaje descentralizado es un objetivo emergente e importante, que puede ser más difícil de lograr en el entorno sin un servidor central confiable.
Métodos de cuantificación y compresión de gradiente
En aplicaciones potenciales, los clientes a menudo estarían limitados en términos de ancho de banda de comunicación disponible y uso de energía permitido.
Traducir y generalizar algunos de los esquemas de comunicación comprimidos existentes desde el entorno facilitado por el orquestador centralizado al entorno completamente descentralizado, sin afectar negativamente la convergencia, es aun una de las lineas de investigación activas, siendo una de las principales soluciones planteadas, diseñar algoritmos de optimización descentralizados que naturalmente den lugar a escasas actualizaciones.
Privacidad
Un desafío importante sigue siendo evitar que cualquier cliente reconstruya los datos privados de otro cliente a partir de sus actualizaciones compartidas, manteniendo un buen nivel de utilidad para los modelos aprendidos.
La Differential privacy es el enfoque estándar para mitigar tales riesgos de privacidad. En el federated learning descentralizado, esto se puede lograr haciendo que cada cliente agregue ruido localmente, pero desafortunadamente, tales enfoques de privacidad local a menudo tienen un gran costo en utilidad. Además, los métodos distribuidos basados en la agregación segura o la mezcla segura que están diseñados para mejorar el equilibrio entre la utilidad y la privacidad en la configuración FL estándar no se integran fácilmente con algoritmos completamente descentralizados.
Otra posible dirección para lograr mejores compensaciones entre privacidad y utilidad en algoritmos completamente descentralizados es confiar en la descentralización misma para ampliar las garantías de privacidad diferencial, por ejemplo, considerando las relajaciones apropiadas de la privacidad diferencial local.
Desafíos prácticos
Una pregunta ortogonal para el aprendizaje completamente descentralizado es cómo se puede realizar en la práctica.
Blockchain es un distributed ledger compartido entre usuarios dispares, que hace posibles las transacciones digitales, incluidas las transacciones de criptomonedas, sin una autoridad central. En particular, los smart contract permiten la ejecución de código arbitrario sobre la blockchain.
En términos de federated learning, el uso de la tecnología podría permitir la descentralización del servidor global mediante el uso de smart contract para agregar modelos, donde los clientes participantes que los ejecutan podrían ser diferentes empresas o servicios en la nube.
Sin embargo, los datos de las blockchain están disponibles públicamente de forma predeterminada, lo que podría desalentar a los usuarios a participar en el protocolo de federated learning descentralizado, ya que la protección de los datos suele ser el principal factor de motivación.
Para abordar tales preocupaciones, podría ser posible modificar las técnicas existentes de preservación de la privacidad para que encajen en el escenario del federated learning descentralizado.
En primer lugar, para evitar que los nodos participantes exploten las actualizaciones de modelos enviadas individualmente, se podrían usar los protocolos de agregación segura existentes manejando efectivamente el abandono de los participantes a costa de la complejidad del protocolo [Articulo]
Un sistema alternativo sería hacer que cada cliente haga un depósito de criptomonedas en la cadena de bloques y que se le penalice si abandona durante la ejecución. Sin la necesidad de manejar los abandonos, el protocolo de agregación segura podría simplificarse significativamente.
Otra forma de lograr una agregación segura es utilizar un smart contract confidencial como el que permite el Protocolo Oasis que se ejecuta dentro de enclaves seguros. Con esto, cada cliente podría simplemente enviar una actualización del modelo local cifrado, sabiendo que el modelo se descifrará y agregará dentro del hardware seguro a través de la certificación remota.
Para evitar que un cliente intente reconstruir los datos privados de otro cliente explotando el modelo global, se ha propuesto la client-level differential privacy. La client-level differential
privacy se logra agregando ruido gaussiano aleatorio en el modelo global agregado que es suficiente para ocultar la actualización de cualquier cliente individual.
En el contexto de la blockchain, cada cliente podría agregar localmente una cierta cantidad de ruido gaussiano después de los pasos de descenso del gradiente local y enviar el modelo a la cadena de bloques. La escala de ruido local debe calcularse de manera que el ruido agregado en blockchain pueda lograr la misma privacidad diferencial a nivel de cliente.
Finalmente, el modelo global agregado en blockchain podría cifrarse y solo los clientes participantes tienen la clave de descifrado, lo que protege el modelo del público.